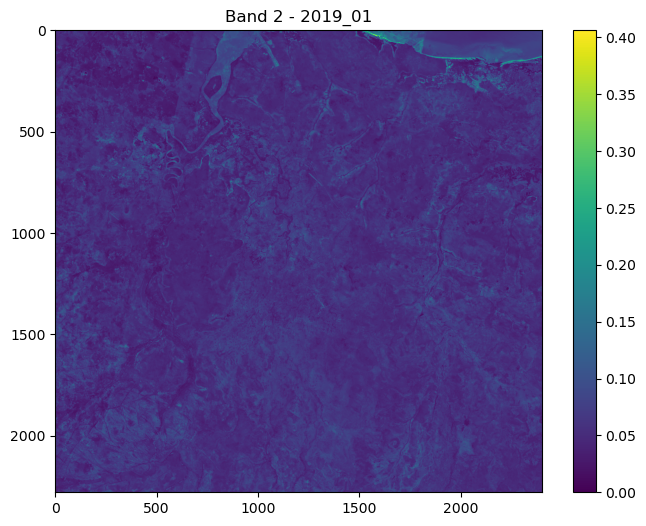
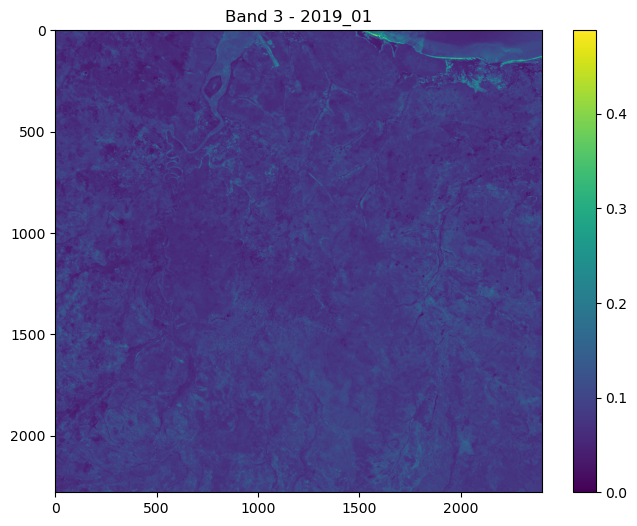
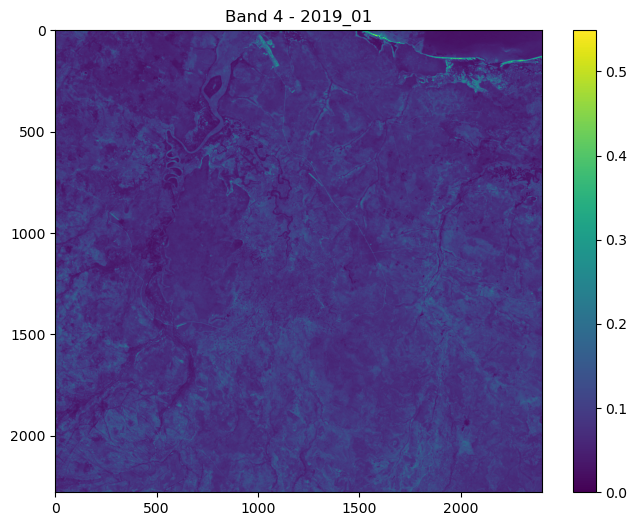
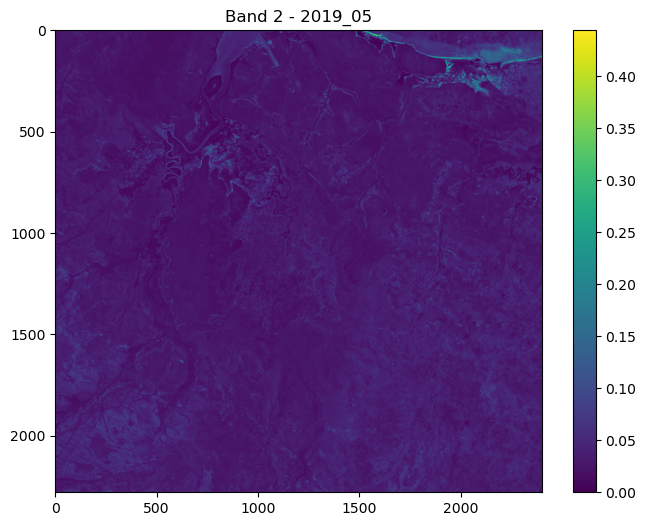
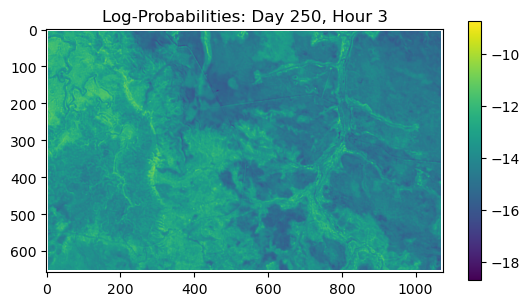
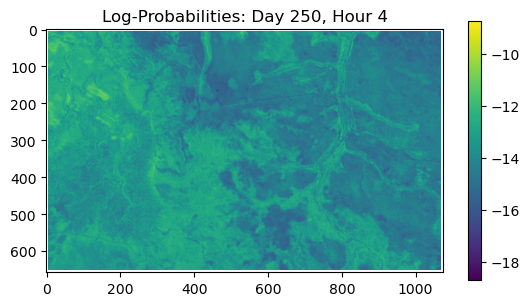
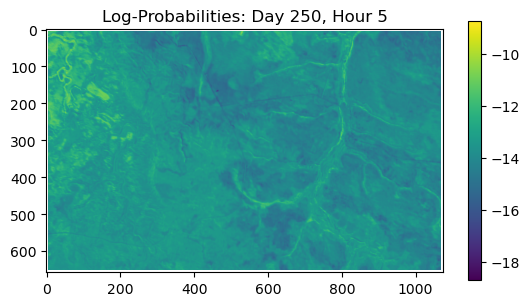
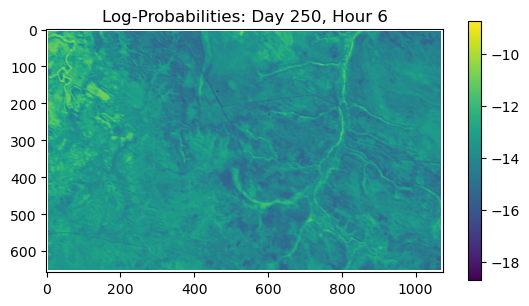
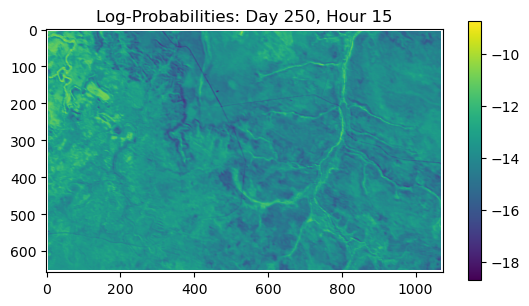
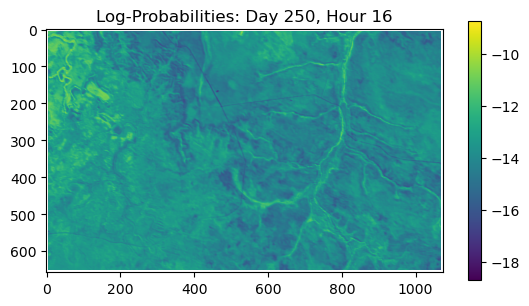
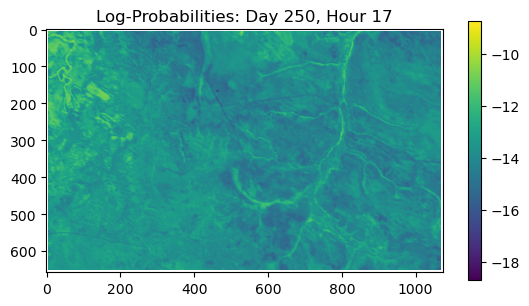
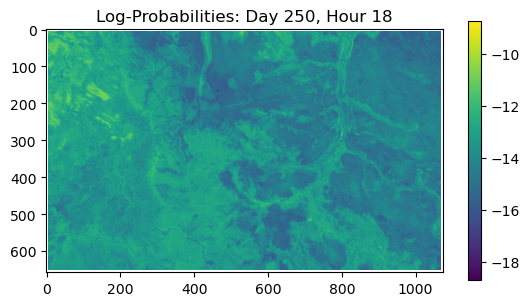
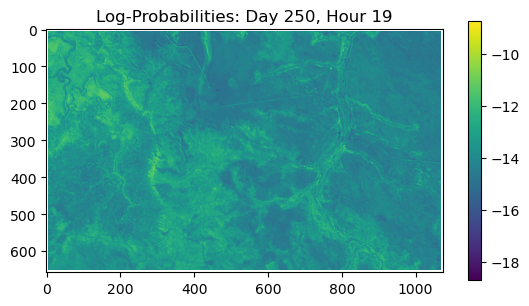
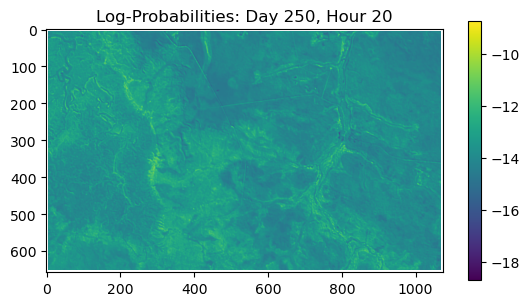
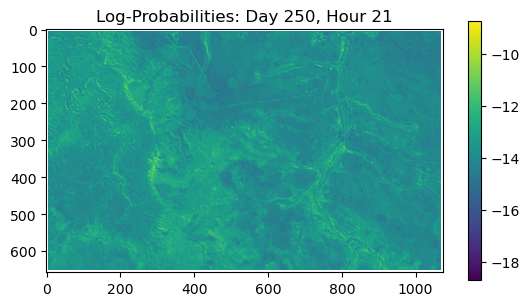
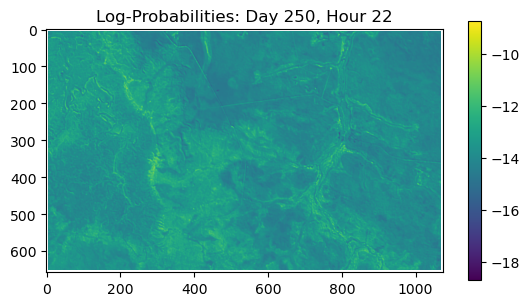
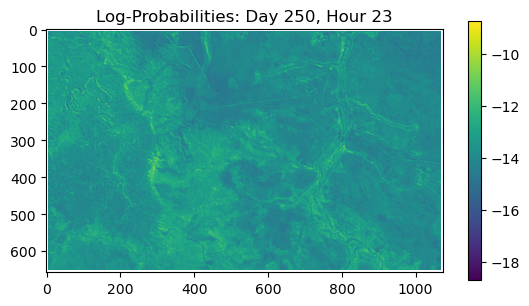
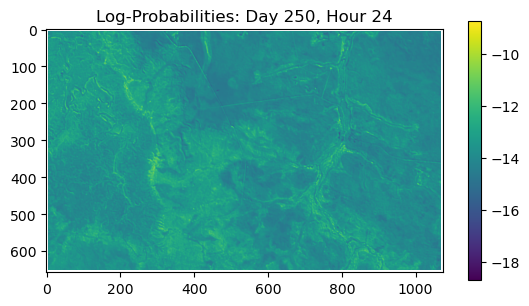
ConvJointModel(
(scalar_grid_output): Scalar_to_Grid_Block()
(conv_habitat): Conv2d_block_spatial(
(conv2d): Sequential(
(0): Conv2d(17, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(4, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): Conv2d(4, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(conv_movement): Conv2d_block_toFC(
(conv2d): Sequential(
(0): Conv2d(17, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(4, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): ReLU()
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
)
)
(fcn_movement_all): FCN_block_all_movement(
(ffn): Sequential(
(0): Linear(in_features=2500, out_features=128, bias=True)
(1): Dropout(p=0.1, inplace=False)
(2): ReLU()
(3): Linear(in_features=128, out_features=128, bias=True)
(4): Dropout(p=0.1, inplace=False)
(5): ReLU()
(6): Linear(in_features=128, out_features=12, bias=True)
)
)
(movement_grid_output): Params_to_Grid_Block()
)